Abstact
Quantitative analysis of animal behavior and biomechanics requires accurate animal pose and shape estimation across species,
and is important for animal welfare and biological research. However, the small network capacity of previous methods and limited multi-species dataset leave this problem underexplored.
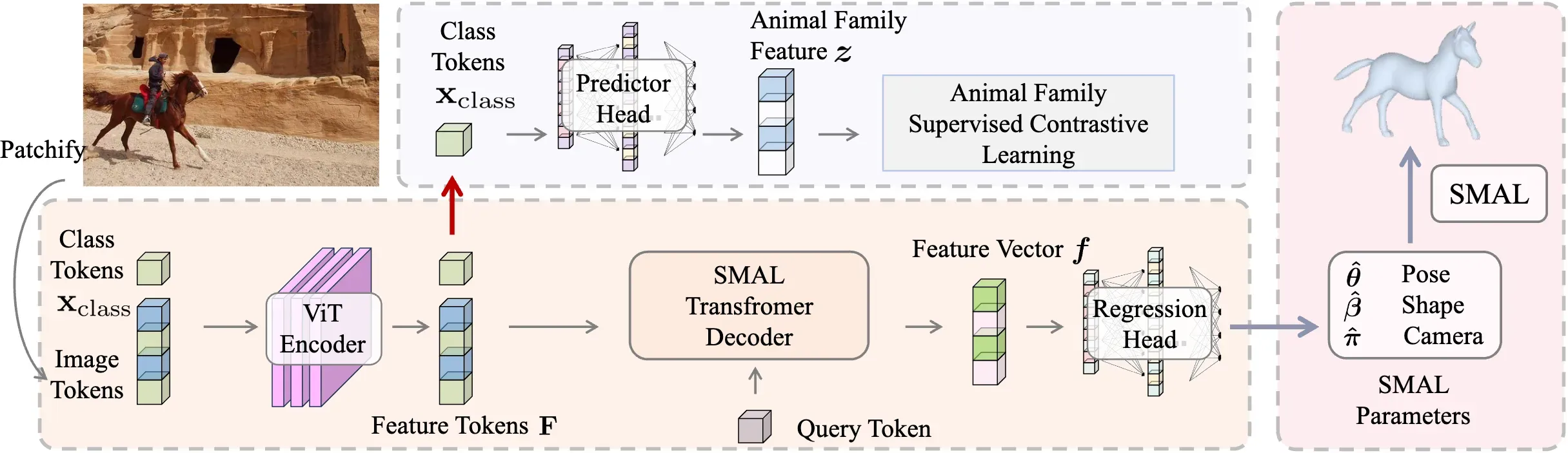
To this end, this paper presents AniMer to estimate animal pose and shape using family aware Transformer, enhancing the reconstruction accuracy of diverse quadrupedal families.
A key insight of AniMer is its integration of a high-capacity Transformer-based backbone and an animal family supervised contrastive learning scheme,
unifying the discriminative understanding of various quadrupedal shapes within a single framework. For effective training,
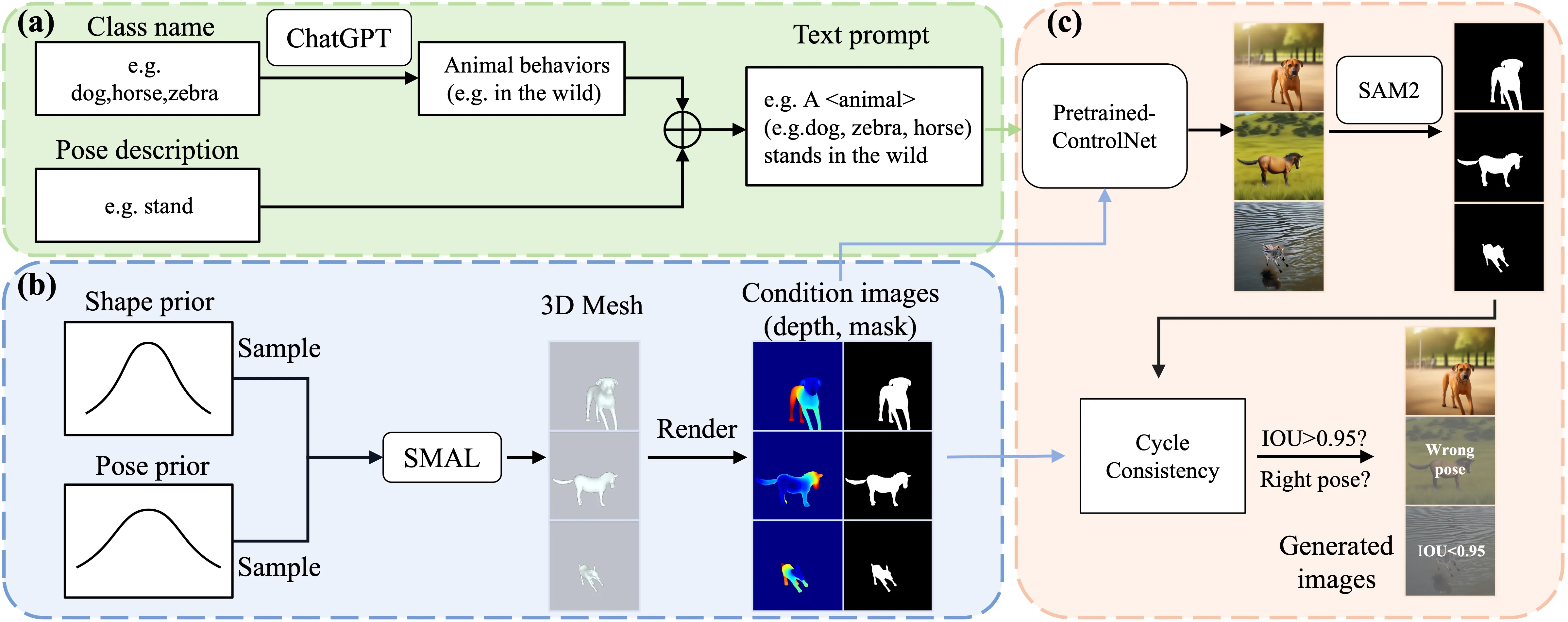
we aggregate most available open-sourced quadrupedal datasets, either with 3D or 2D labels. To improve the diversity of 3D labeled data,
we introduce CtrlAni3D, a novel large-scale synthetic dataset created through a new diffusion-based conditional image generation pipeline.
CtrlAni3D consists of about 10k images with pixel-aligned SMAL labels. In total, we obtain 41.3k annotated images for training and validation.
Consequently, the combination of a family aware Transformer network and an expansive dataset enables AniMer to outperform existing methods not only on 3D datasets like Animal3D and CtrlAni3D,
but also on out-of-distribution Animal Kingdom dataset.
Ablation studies further demonstrate the effectiveness of our network design and CtrlAni3D in enhancing the performance of AniMer for in-the-wild applications.